Git Commands Most Used
Date: 2021-01-13
Reference: git MOC
Tags: #git
1. [How to] Folder (or files) already Have Been Tracked in Git but You no Longer want Them to Be Tracked? Then Untrack the Folder (files) and then Add into Gitignore
#folder
git rm -r --cached snippets/
#git rm -r --cached .DS_Store
git add .gir
git commit -m "untrack files"
2. Update Local Files and force to Overwrite Remote files
git checkout
git add .
git commit -m "local changes"
ga .
3. Push Changes to Remote Repo (forced update)
git push --force
# alias
gpf!='git push --force'
4. [How to] List All files tracked by Git
git ls-tree -r master --name-only
#alias
gtn=git ls-tree -r master --name-only
5. Git Commit and Add One-liner (requires Setting up function)
acm "message"
# same as
git add .
git commit -m "message"
6. Push to Remote Repo
- go to github
- login
- create repo
git remote add origin https://github.com/MaksimZinovev/aerofiler-pytest
git push -uf origin master
# OR
git push -u origin master
origin means push commits to remote repository URL with short name origin. master means master branch.
-u combined with origin master sets the default remote repository and branch to origin and master respectively for the current branch. Next time, when we need to push some commits, we just have to use git push.
The
-uis a shortcut for the--set-upstream-toflag which should be used while pushing the very first commit. However, you can use--trackflag to track the current branch with a remote branch.
7. How to Find the N Largest Files in a Git Repository?
git ls-files | xargs ls -l | sort -nrk5 | head -n 10
8. What is the Actual Size of Your Git Repository?
git count-objects -vH
9. Delete Repository from GitHub
Oopen repository pagerem > Settings > Options > Danger Zone
10. Git Initial Setup
git config --global user.name 'Maksim Zinovev'
git config --global user.email 'maksimzinovevsubmit@gmail.com'
git config --global core.editor "nano"
git config --global --list
11. Verify if a Local Repository is Tracking the Remote Repository
git remote -v
12. Move All Changed, Deleted and New Files from the Working Area to the Staging Area. This Process also Known as staging.
git add -A
You can also use
git add -u,git add .andgit add *to stage all files at once. They work a little differently thangit add -A.git add -Aadd all new, modified and deleted files (tracked+untracked) to staging area.git add folder/will add all files in that folder with-Aflag.git add -uadds only updated AKA modified+deleted (tracked only) files to staging area.git add .acts likegit add -Abut it will only pick up files from the current directory you are in (check terminal). Don’t use_git add *_command, explained here (https://stackoverflow.com/a/26042516/2790983)
13. Unstage Files
If you added some files in the staging area by mistake, then you can use the following command to unstage them.
git reset add.js
# now "add.js" is untracked
14. Commit
Since, we are done with it, we can stage it back again with git add add.js. It’s time to time to make our first commit. To create a commit, use the following command.
git commit -m "initial commit"
Once you’ve completed a section of work it’s time to commit. Commits should be done atomically. This means that commits should be self contained and no code/bug fixes should span multiple commits. You shouldn’t be committing half broken code or bunching lots of things together.
- Status
git status
will show you the status of the working directory.
16. Log
git log will show you the commit hash, the author and the commit message along with other details.
To see file that was changed or added in a commit, use
--statargument withgit loglike thisgit log --stat.
git log --oneline
will output the short commit number and commit title
17. Warning: in the Working Copy of LF Will Be Replaced by CRLF the next time Git Touches it
Set up the CRLF and the problem will "disappear"
# Option 1:
git config --global core.autocrlf false
# Option 2:
`git config --global core.safecrlf false`
18. To Change the Message of the Previous Commit, Use the following Command.
git commit --amend -m "Initial Commit"
19. Add File to the Previous Commit
first stage it
git add -A
and then use
git commit --amend
- Reset repository to a revision
It is possible that you made a commit that you didn’t intend to make. So, what about that? HEAD is pointer to the last commit in Git history.
We want our repository (actually branch we are in, explained later) to point to the commit with the hash that starts wit 852309 and forget as if commits after that ever existed. There are a few ways to achieve this.
git reset --soft 852309will remove all commits after commit852309and will bring all changed code after that into the staging area. You don’t need to use the full hash of a commit. All commits after this commit are then removed from git history.git reset --mixed 852309will remove all commits after commit852309and will bring the changed code after that to the working area. This command is the same asgit reset 852309.git reset --hard 852309will remove all commits after commit852309and destroy all changed code after that. This will also remove the changed files in the working or staging area. Hencegit reset --hard HEADis also used to get rid of all the changes whether it is inside the working area or the staging area. One important thing to remember is that all untracked files (newly created files) will not be removed.
- Use
git reset 852309to remove all commits after commit852309and l bring the changed code after that to the working area. - Make additional changes in working area if required.
- Use
git diffto see what code changes between the current state of the files and the state of the files in the previous commit git add -A- add to staging area.git commit- Now instead of multiple commits we have just one commit after
852309and required changes. git push
20. Fixing Common Mistakes
There will be some cases where changes in the code or a repository happened due to an error, like unzipping of a tar file which added thousands untracked folders and files, or files changed due to some system error. To avoid such problems, use the following approach.
Let’s say by mistake, add.js file was changed and we don’t want any changes in this file. In that case, you can use the command below which will set state of the above file to state of the file in HEAD commit (pointer to the last commit). But for this, add.js must be in the working area else it won’t work.
If you want to get rid of all the modifications made to tracked files made so far, whether files are in the working area or staging area, use the command below. This will try to remove all commits after HEAD and remove all local changes. But since there is no commit after HEAD, as HEAD is the last commit, it will only end up removing local changes.
git reset --hard HEAD// orgit reset --hard
But you can use also
git stashinstead of above command. We will talk about this command in an upcoming lesson.
If you have lots of untracked files or folders in the repository which you want to remove, then you can use the command below. This will come in handy in the unzip situation we discussed above. -d stands for include directories as well and -f stands for forced operation. There are other options available which you can find here https://git-scm.com/docs/git-clean.
git clean -f -d
21. Head
HEAD is just a pointer to the last commit in a currently checked out branch (the current branch we are in). Hence whenever I say HEAD of master branch, it doesn’t mean, master branch doesn’t have different HEAD than other branch. It means HEAD when we are in master branch. So bear with me on this one.
22. Branch
When we create a new branch, we are creating a new tuple with a branch name and a commit. The commit for the new branch is taken from the last commit of another branch. If we are inside master branch and we instructed Git to create new branch, Git will pick up last from master branch. Once we switch the branch, HEAD will point to the last commit of the current branch.
Let’s create a branch with the name dev. To create a branch, first, we need to make sure we are inside the correct branch with the begin with. Right now, we are inside the master branch and you can verify that by looking at your terminal or by checking how many branches are present in the repository. The one with an asterisk is the branch you are currently in.
git branch

(git branch)
To create a branch, you need to use the following command.
git branch dev
(git branch dev)
This will create dev branch but we are still under master branch. To enter inside dev branch, we need to use checkout the branch using the command below.
git checkout dev
when we will create a new commit, it will be added to the top becoming HEAD of the dev branch but the HEAD of the master branch won’t be changed. At that point, their files state will be different.
To check all local and remote branches, use git branch -a. So far there is only one remote branch.
23. Fetch
You can use git fetch at any time to update your remote-tracking branches. Let’s create a remote branch from GitHub.
To check all local and remote branches, use git branch -a
git fetch
git branch -a
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (dev)
$ git branch -a
* dev
master
remotes/origin/HEAD -> origin/master
remotes/origin/master
remotes/origin/testing-remote-branch
24. Set the upstream for the Local Branch
If this branch doesn’t exist on the remote repository, it will be created.
git branch dev
git checkout dev
git push -u origin dev
The above command will create dev branch on remote repository and our local dev branch will track it.
25. Merge
Let’s say that continuous integration test on remote dev branch ran well and you (or admin) now have to merge changes made in your dev branch to the master branch. Merging happens between two branches, technically, it is careful mixing of commits of two branches.
Since, we need all changes made in the dev branch to sync with the master branch, we have to checkout master branch:
git checkout master
When we checkout out the
masterbranch, we are referencing a different Git history because our HEAD is different. That means the state of the files associated with this HEAD would be different. Hence Git changes the content of the files in the repository according to that state. You can visualize by openingdivide.jsfile in editor when you are indevbranch and monitor that file when you checkoutmasterbranch. You will see content of that file changes as we move from one branch to another branch. You could also see some files appear and disappear.
Since we are now in the master branch, we must pull code from the remote repository before doing anything, always do this. This way, we don’t miss out on any development happened on master branch (done by other developers) whilst the development of dev branch.
git pull
Now, we have to merge the dev branch into the master branch. To check if any branches ever merged with current branch which is master, you can use the command below.
git branch --merged

(git branch --merged)
From the above output, it is clear that no other branches were ever merged in master branch. Since we are already under the master branch, the following command will merge the dev branch with the current branch.
git merge dev

(git merge dev)
The above command also shows files that were changed. You can also verify the merger by executing git branch --merged command. If we see the git history of master branch now, we can see any commits made in the dev branch appears in master branch.

(git log)
Now we just have to sync the local master branch with the remote one. This is done using the same old git push command.
Example commands and output:
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (dev)
$ git add -A
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (dev)
$ git commit -m "commit2 in dev branch"
[dev d765f7a] commit2 in dev branch
1 file changed, 44 insertions(+), 1 deletion(-)
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (dev)
$ git checkout master
Switched to branch 'master'
Your branch is up to date with 'origin/master'.
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (master)
$ git branch --merged
* master
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (master)
$ git merge dev
Updating e5c681f..d765f7a
Fast-forward
resources/learning-tools/git/git-short-commands.md | 147 +++++++++++++++++++--
unsorted/Payoneer support.md | 7 +-
2 files changed, 140 insertions(+), 14 deletions(-)
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (master)
$ git branch --merged
dev
* master
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (master)
$ git log
commit d765f7a915b32947966953c3464d1a8c54b60e88 (HEAD -> master, dev)
Author: Maksim Zinovev <maksimzinovevsubmit@gmail.com>
Date: Thu Dec 22 18:57:30 2022 +0600
commit2 in dev branch
commit 8134df53863ec32a89e9d664d8155a40efc24457 (origin/dev)
Author: Maksim Zinovev <maksimzinovevsubmit@gmail.com>
Date: Thu Dec 22 18:37:45 2022 +0600
commit1 in dev branch
commit e5c681fbcfb0cefbcab1263b3c449e600f3ab51e (origin/testing-remote-branch, origin/master, origin/HEAD)
Author: Maksim Zinovev <maksimzinovevsubmit@gmail.com>
Date: Thu Dec 22 12:42:13 2022 +0600
update2 2022-12-22
commit 702d0e27f5690627f66598cdbead46c4d4c2798c
Author: Maksim Zinovev <53397443+MaksimZinovev@users.noreply.github.com>
Date: Tue Dec 20 20:03:57 2022 +0600
update folder name TAX Return 2020 Company Annual report
commit 123bbe6906b68b331a7f881c23140b697d2450c2
Author: Maksim Zinovev <53397443+MaksimZinovev@users.noreply.github.com>
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (master)
$ git push
Enumerating objects: 11, done.
Counting objects: 100% (11/11), done.
Delta compression using up to 4 threads
Compressing objects: 100% (6/6), done.
Writing objects: 100% (6/6), 1.05 KiB | 1.05 MiB/s, done.
Total 6 (delta 5), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (5/5), completed with 5 local objects.
To https://github.com/MaksimZinovev/work-obsidian-vault.git
e5c681f..d765f7a master -> master
maksim@DESKTOP-RFLIR6R MINGW64 ~/work (master)
$
26. Delete Branch
If we are done with dev branch and we don’t need it anymore, then we can just delete it using the command below. This will delete the local dev branch only.
git branch -d dev
To delete the remote dev branch as well, you need to use the command below.
git push --delete origin dev
27 Fixing Common Mistakes
We have seen so far that if you are working with a team of people, then you should not touch the production branch which in our case is master. But what if you accidentally forgot to switch branch and made commits inside the master branch? You can’t just remove your commits using git reset and redo the work. That would be painful. In that case, we could use couple of techniques including cherry-picking.
Let’s first create a commit inside the master branch
28. Reflog
git reflog prints a complete list of previous operations.
$ git reflog
0b5bfb0 (HEAD -> master) HEAD@{0}: commit: create canvas diagram for cherry-picking
d765f7a (origin/master, origin/HEAD, dev) HEAD@{1}: merge dev: Fast-forward
e5c681f (origin/testing-remote-branch) HEAD@{2}: checkout: moving from dev to master
d765f7a (origin/master, origin/HEAD, dev) HEAD@{3}: checkout: moving from master to dev
e5c681f (origin/testing-remote-branch) HEAD@{4}: checkout: moving from dev to master
d765f7a (origin/master, origin/HEAD, dev) HEAD@{5}: commit: commit2 in dev branch
8134df5 HEAD@{6}: commit: commit1 in dev branch
e5c681f (origin/testing-remote-branch) HEAD@{7}: checkout: moving from master to dev
e5c681f (origin/testing-remote-branch) HEAD@{8}: reset: moving to e5c681
61743cf HEAD@{9}: commit: update3 2022-12-22
e5c681f (origin/testing-remote-branch) HEAD@{10}: commit (amend): update2 2022-12-22
ed22f14 HEAD@{11}: commit (amend): update2 2022-12-22
d4d8b22 HEAD@{12}: commit: update 2022-12-22
702d0e2 HEAD@{13}: clone: from https://github.com/MaksimZinovev/work-obsidian-vault.git
29. Revert
What if I made a commit in the wrong branch and pushed it? Well, that would be wrong and you would not want to remove commits which are published. This is because you will end up rewriting the history of remote branch when you next time push the branch, but other people have the commit that you deleted. This can cause lot of problems.
Instead, what we want is to create a new commit that will undo the work we have done. Let’s create a simple commit in master branch.
// subtract.js// return subtraction of two numbersfunction subtract(a, b, bMINUSa) { if (bMINUSa === true) { return b - a; } else { return a - b; }};
We made a change to subtract.js file, we are going to create a commit from it.
git commit -am "extra feature in subtract function"git push
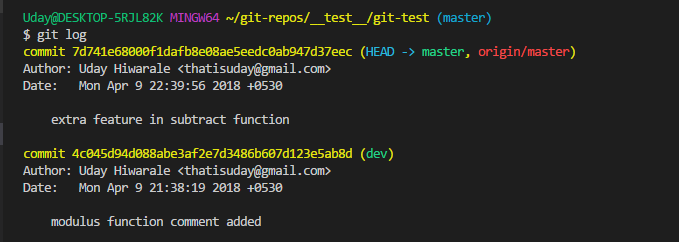
(git log)
Now, our commit is on the remote branch as well. Then we realized our mistake that we were not supposed to make that commit. Since our commit is present on the remote branch, we can’t simply remove it from our local branch and publish it again, because, in between, other developers might have synced the branch or cloned the repo.
Hence, we have to revert the changes. This is done using git revert which creates a new commit by reverting all the changes in a commit. Since, we want to revert all change in commit 7d741e, we need to use the command below.
git revert 7d741e
It will open up vim editor with new commit information which we would like to change.

(git revert 7d741e)
You can also use
git revert 7d741e --no-editinstead which would skip the editor dialog.
After running this command and doing modifications to revert commit message, your git history will look like below.

(git log)
We can see that revert created a new commit and deleted changes in the subtract.js file which you can verify by looking content of the file. You can also verify this by using git diff between two commits.
git diff 01f8a6a 4c045d9
Which will output nothing because there is no difference between reverted commit and the commit before changes were made.
Since we did undo the changes which were not supposed to be on the master branch, we should push this revert commit to the remote master branch. This way other remote master branch do not have faulty updates and other people’s history will remain consistent with the remote repository.
- Stashing changes
Stashing means secretly hiding something and when we stash changes, they are stored in a safe place. This is where git reset --hard contradicts. Git hard reset will get rid of changes in tracked files while stash will do the same but it can save the changes in a secret location. These changes can be re-applied if needed.
31. Merge Conflicts
You can’t avoid a situation when you have made some changes to a line in a file and somebody else also have made changes to the same line in the same file. If the other developer has published his/her changes to the remote repository and you are trying to publish your changes after that, Git won’t allow you to publish your changes. This happens because Git is confused about whether your changes are important or somebody else’s.
Updated in remote branch
I have made a commit in the remote repository by modifying add.js file’s first line and we don’t have that commit in our local repository. Now, let’s make similar changes in the local repository.

(add.js)
Since we are done with our changes and we don’t have any idea if somebody else has worked on same line of the same line, we are going to make a commit.

Now, let’s try to push it to the master branch of the remote repository.
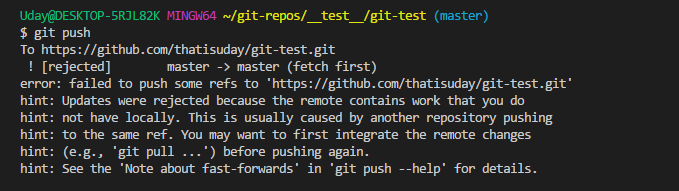
(git push)
Wow, something went wrong. From the error message, we can tell that push was unsuccessful and some ref (changes) on remote repository conflicts with our changes. Hence, first, we need to bring those changes (commits) in our local repository and deal with them. We will use git pull to sync the remote repository’s master branch with local repository’s master branch.

(git pull)
Git pull shows that there was a merge conflict in add.js file.
If you are asking why it is showing merge conflict because we did not use
git mergecommand but that’s what Git does when you usegit pullcommand which is equivalent ofgit fetch && git merge origin/master. So, it is merging ofremote/masterbranch withmasterbranch.
When there is a merge conflict, Git will add conflicting changes contained remote repository to the file(s) rather than adding commits to Git history. Hence, git log will print the same history you had before the git pull.

(git log)
Since some files are changed, you can see these files in the staging area.

(git status)
git status also prints that we have merge conflicts and we have some unmerged paths in add.js. Let’s see how add.js looks like.
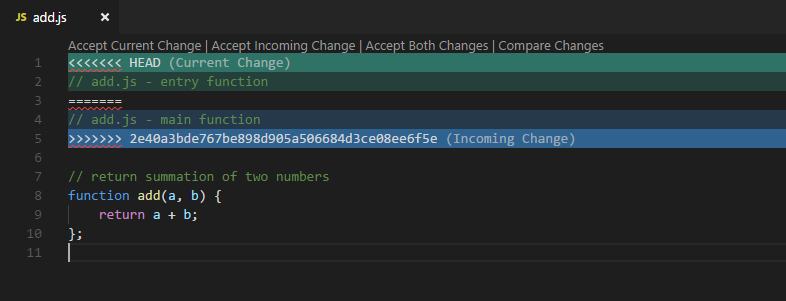
(add.js)
I am using VSCode editor and it is intelligent enough to spot error by highlighting code lines. When merge conflict occurs, Git will put conflicting lines of code inside <<<<<<< HEAD and >>>>>>> tags. It will also show the commit hash of conflict which is present on the remote branch.
To fix this, you need to remove these markers and make a choice on which line is important. I feel that my line makes more sense and other people approved it, hence I am going to put things as they were before the merge.

(edited add.js file)
Now that we made changes to add.js file, we have to create another commit. When we will create commit from conflicting file, Git will automatically add a conflicting remote commit to the branch.

(git log)
Now, we can push these commits to remote repository and git push hopefully will work just fine.
What we saw is just one way to solve merge conflicts. Also you can use git merge --abort (_git reset --merge_ for older Git versions) to abort the merge when you do git pull, which will remove conflict markers from the file. But you still have merge conflicts when you do git pull next time.
If you think other developer’s work is more important and your changes should be just ignored then you can reset the HEAD of your branch to remote commit with --merge flag. We can see remote commit hash from the conflicting marker in add.js file which is 2e40a3. Hence git reset --merge 2e40a3 will remove your commit (HEAD) and replace it with 2e40a3 commit. This will also change conflicting files to remote version. Check your git log after that.
Merge conflicts can happen at any time and you should be ready for them. One common safe practice is to always keep your local branch in sync with the remote branch by doing git pull. Also, keep pushing commits as soon as you are done with them. That will minimize conflicts by a large extent.
Add
git add -Astages all changes- =
git add .+git add -u
- =
git add .stages new files and modifications, ~without deletions~ (on the current directory and its subdirectories)- [!] For Git >= 2.0,
git add .will add deletions! Use flag--ignore-removalto ignore deletion - [!] Therefore,
git add -Ais redundant for Git >= 2.0
- [!] For Git >= 2.0,
git add -ustages modifications and deletions, without new files
Combine Add and Commit
git commit -am "commit message"
is equal to
git add -u
git commit -m "commit message"
Alias
git config --global alias.ac "commit -am"
git ac "commit message"
is equal to
git commit -am "commit message"
Branch
# Create a branch
git branch -M main
# Rename a branch
git branch -M master main
Log in Terminal
To get better log info like in the GUI
git log --graph --oneline --decorate
Stash
stash store your changes without commit, remove them now, and pop out when you need them again
# Store all your changes without commit, and hide them
git stash
# Pop out your hidden changes
git stash pop
# Stash your changes with a given name
git stash save "your stash name"
# Show all your stashes
git stash list
# Apply a certain stash in the list
git stash apply index
Ignore
To ignore some files or directories, add them to the .gitignore file. However, this will not work for files/dirs that have already been tracking. To remove those files/dirs from git tracking (not delete them), use
git rm -r --cached path_to_file_or_dir
New Branch
# Create a new branch called new_branch
git branch new_branch
# Checkout (switch) to the new branch
git checkout new_branch
These two commands have a shorthand:
git checkout -b new_branch
Discard Branch
When a branch is pulled/merged into main, it is no longer needed.
git branch -d patch # delete branch
git fetch -p # stop tracking obsolete remote branches (prune)
Remotes
# View the remotes
git remote -v
# Add a remote called origin
git remote add origin git@github.com:zcysxy/repo.git
# Change the url of the remote origin
git remote set-url origin https://github.com/zcysxy/repo.git
When forking an other's repo, remember to add the other's repo as an upstream repo.
git remote add upstream git@github.com:yiyi/repo.git
Forking and Making Pull Requests Best Practice
- Set the original repo as the upstream repo.
- Switch to a new branch before making any changes.
- Make a pull request from a new branch other than
main/master. - After the pull request is merged into the original repo, pull it into your own
main/masterbranch. - Delete the obsolete branch.
git branch -D obsolete-branch
Discard Changes
# Restore several files
git restore file1 file2 file3
# Restore all
git restore .
Get Files from Other Branches
To get files from other branches, you can either use checkout command or restore command.
# main branch
git checkout other_branch -- file1 file2
# or
git restore --source other_branch -- file1 file2
Show Tracked Files
List all the files currently being tracked under the branch master
git ls-tree -r master --name-only
Remote Status
To show what's going on in the remote branches, you need to fetch/update them first, then compare the differences.
# Method 1
git fetch origin
git diff origin/master
git merge origin/master
# Method2
git remote update
git status
List Files
Ls-files
git ls-files # Show information about files in the index and the working tree
[-c|--cached] [-d|--deleted] [-o|--others] [-i|--|ignored]
[-s|--stage] [-u|--unmerged] [-k|--|killed] [-m|--modified]
[--directory [--no-empty-directory]] [--eol]
[--deduplicate]
[-x <pattern>|--exclude=<pattern>]
[-X <file>|--exclude-from=<file>]
[--exclude-per-directory=<file>]
[--exclude-standard]
[--error-unmatch] [--with-tree=<tree-ish>]
[--full-name] [--recurse-submodules]
[--abbrev[=<n>]] [--] [<file>…]
Ls-tree
git ls-tree -r main --name-only
ls-tree is better than ls-files because ls-files may differ from the --work-tree.
Garbage Collection
To "collect the garbage" in the .git folder and reduce its size, use
git gc
# or spend more time optimizing using
git gc --aggressive
This command actually executes a bundle of other internal subcommands like git prune, git repack, git pack and git rerere. These subcommands identify any Git objects that are outside the threshold levels set from the git gc configuration, and then compress, or prune them accordingly.
Global .gitignore
You can create a global .gitignore file to ignore files for all git repositories. When you created that file, run the following command
git config --global core.excludesfile <path_to_your_gitignore_global>
Separate Git Directory
Sometimes, you don't want the .git directory to be in the same directory as the working tree (for example, to prevent sync issues).
cd ~/work/dir # working dir
git init –separate-git-dir ~/work/dir.git # git dir in the parent dir
Bring just One File from another branch
git checkout main # first get back to main
git checkout experiment -- app.js # then copy the version of app.js
# from branch "experiment"